- ai爬虫实践报告
- 首页 > 2024ai学习栏目 人气:11 日期:2025-03-08 10:04:50
 文章正文
文章正文
一、爬虫实践报告简介
本报告详细介绍了利用人工智能技术实行网络爬虫的实践过程。通过Python编程语言结合requests模块、BeautifulSoup解析库以及re正则表达式实现了对指定网站数据的自动抓取、解析和存。以下是报告的主要内容:
1. 爬虫技术背景及意义
2. 实践目标与任务
3. 爬虫工具与库的选择
4. 爬虫流程与步骤
5. 数据解析与提取
6. 数据存与展示
7. 实践成果与总结
二、具体内容
1. 爬虫技术背景及意义:随着互联网的发展大量数据呈现在网络上怎么样高效获取这些数据成为关键。爬虫技术能自动化地收集、整理网络数据,为数据分析、挖掘提供基础。
2. 实践目标与任务:本次实践以百度百科中《青春有你2》参赛选手信息为对象,实数据的爬取。


3. 爬虫工具与库的选择:采用Python语言,利用requests模块发送请求,BeautifulSoup实行数据解析,re正则表达式辅助提取数据。

4. 爬虫流程与步骤:模拟浏览器发送请求,获取响应数据,解析并提取有用信息,最后保存到本地或数据库。
5. 数据解析与提取:通过定位目标数据,采用BeautifulSoup的查找方法或re正则表达式提取所需信息。

6. 数据存与展示:将提取的数据存到本地文件或数据库中,并实可视化展示。
7. 实践成果与成功爬取了《青春有你2》参赛选手信息,增强了对爬虫技术的理解和应用能力为后续数据分析奠定了基础。

报告《全面解析网络爬虫实践:从原理到高级应用技巧的详尽实验记录》

# 全面解析网络爬虫实践:从原理到高级应用技巧的详尽实验记录 ## 引言 随着互联网技术的飞速发展大量的数据信息被存在各个网站中。为了高效地获取这些数据,网络爬虫技术应运而生。本文将通过一次详尽的实验记录,全面解析网络爬虫的原理、实践过程以及高级应用技巧,评估不同等待机制在Python动态网页爬虫中的利用效果和性能差异。 ## 一、实验背景与目的 ### 实验背景 互联网上的数据量急剧增长,怎样有效地获取所需数据已成为一个不可忽视的疑问。Python作为一种功能强大的编程语言,可用来编写网络爬虫实现自动化
网络爬虫实训心得:实报告与实验总结汇编
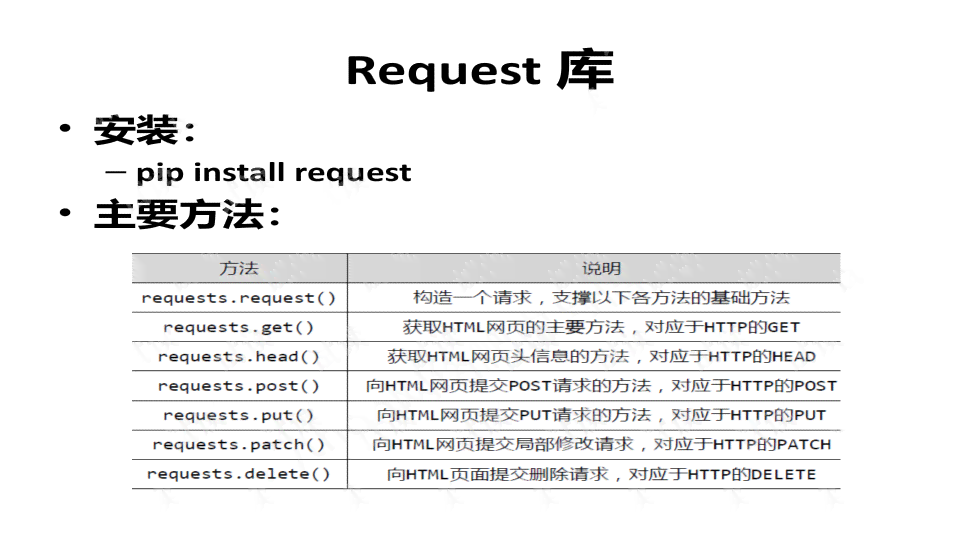
随着互联网技术的飞速发展网络爬虫作为一种获取网络数据的要紧工具已经广泛应用于各个领域。在这个信息爆炸的时代怎样高效地从海量数据中提取有价值的信息成为了一个亟待应对的疑惑。本文将围绕我在网络爬虫实训进展中的所学所得分享实报告与实验总结汇编以期为有志于学网络爬虫的同学提供若干借鉴和参考。 一、引言 网络爬虫实训是我大学生涯中的一要紧经历。通过本次实训,我对网络爬虫的基本原理、技术方法和实际应用有了更深入的理解。实训进展中,我遇到了多挑战,但也在解决难题的期间积累了宝贵的经验。以下是我在实训期间的若干心得体会和总结。
爬虫项目实训报告:编写与实践总结及体会

爬虫项目实训报告:编写与实践总结及体会 一、引言 随着互联网技术的飞速发展数据已经成为了一种非常必不可少的资源。而爬虫技术作为一种高效的数据获取手在信息采集、数据分析等方面发挥着关键作用。本文将通过介绍一次爬虫项目实训的过程分析编写与实践中的经验教训以及个人的体会和感悟。 二、实训背景与目的(1) 1. 实训背景:在本次实训中咱们学了爬虫的基本原理和实现方法,涵网页抓取、数据解析、存等环节。通过实训,我们可以更好地理解爬虫技术在现实中的应用和价值。 2. 实训目的:本次实训的主要目的是编写一个简单的爬虫程
网络爬虫实战指南:全方位解析数据抓取策略与合规实践

在数字化时代,数据已成为企业竞争和科技创新的核心资源。网络爬虫作为一种高效的数据抓取工具可以帮助企业迅速获取海量信息。随着网络爬虫技术的广泛应用,合规难题也逐渐凸显。怎样在保证合规的前提下,高效地实行数据抓取,成为多从业者关注的点。本文将全方位解析网络爬虫的数据抓取策略与合规实践,助您轻松应对各类挑战。 一、网络爬虫实践报告合集:揭秘数据抓取全过程 网络爬虫实践报告合集是对网络爬虫项目实过程的详细记录,涵需求分析、技术选型、数据抓取、数据解决、合规审查等环节。以下是对这一部分的优化标题及内容解答。 优化网络爬
'基于爬虫技术的实验报告与心得总结:文库篇'

基于爬虫技术的实验报告与心得文库篇 一、引言 随着互联网技术的飞速发展,大量的数据和信息不断涌现。怎么样有效地获取、应对和分析这些数据,成为了当下亟待解决的疑问。网络爬虫技术作为一种自动化获取网络数据的方法受到了越来越多的关注。本文将基于一次Python爬虫实训实验,对实验过程实梳理,并分享心得体会。 二、实验目的与内容 1. 实验目的 (1)掌握Python爬虫的基本原理和操作方法。 (2)评估不同等待机制在Python动态网页爬虫中的采用效果和性能差异。 (3)培养数据应对和分析能力。 2. 实
爬虫软件实训报告:项目实训与总结感想实践记录及内容梳理

爬虫软件实训报告:项目实训与总结感想实践记录及内容梳理 一、项目背景与目的 在当今信息爆炸的时代怎样高效地从海量的互联网数据中提取有价值的信息成为了一个要紧课题。本次实训旨在通过实践操作深入理解网络爬虫的原理、技术与应用评估不同等待机制在动态网页爬虫中的性能差异,并掌握Python动态网页爬虫的开发与优化方法。 二、项目实训内容 1. 熟悉爬虫基本原理 - 网络爬虫通过模拟浏览器发送HTTP请求,获取网页内容。 - 通过解析网页内容,提取所需信息。 2. 掌握常用爬虫框架 - Sc